정보처리기사 - 데이터 입출력 구현 #46~49
2023. 8. 19. 11:24ㆍ자격증/정보처리기사
46. 반정규화(Denormalization)
46.1 반정규화(Denormalization)
시스템의 성능을 향상하고 개발 및 운영의 편의성 등을 높이기 위해 정규화된 데이터 모델을 의도적으로 통합, 중복, 분리하여 정규화 원칙을 위배하는 행위- 반정규화를 수행하면 시스템의 성능이 향상되고 관리 효율성은 증가하지만 데이터의 일관성 및 정합성이 저하될 수 있음
- 과도한 반정규화는 오히려 성능을 저하시킬 수 있음
- 반정규화의 방법
- 테이블 통합
- 테이블 분할
- 중복 테이블 추가
- 중복 속성 추가
46.2 테이블 통합
두 개의 테이블이 조인(Join)되어 사용되는 경우가 많을 경우 성능 향상을 위해 아예 하나의 테이블로 만들어 사용하는 것- 테이블 통합을 고려하는 경우
- 두 개의 테이블에서 발생하는 프로세스가 동일하게 자주 처리되는 경우
- 항상 두 개의 테이블을 이용하여 조회를 수행하는 경우
- 테이블 통합의 종류
- 1:1 관계 테이블 통합
- 1:N 관계 테이블 통합
- 슈퍼타입/서브타입 테이블 통합
- 슈퍼타입/서브타입 : 슈퍼타입은 상위 개체를, 서브타입은 하위 개체를 의미
46.3 테이블 분할
테이블을 수직 또는 수평으로 분할하는 것| 방법 | 내용 |
|---|---|
| 수평 분할 | - 레코드(Record)를 기준으로 테이블을 분할하는 것 - 레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할 |
| 수직 분할 | - 하나의 테이블에 속성이 너무 많을 경우 속성을 기준으로 테이블을 분할하는 것 - 종류 : 갱신 위주의 속성 분할, 자주 조회되는 속성 분할, 크기가 큰 속성 분할, 보안을 적용해야 하는 속성 분할 |
46.4 중복 테이블 추가
작업의 효율성을 향상시키기 위해 테이블을 추가하는 것- 중복 테이블을 추가하는 경우
- 여러 테이블에서 데이터를 추출해서 사용해야 할 경우
- 다른 서버에 저장된 테이블을 이용해야 할 경우
- 중복 테이블 추가 방법
| 방법 | 내용 |
|---|---|
| 집계 테이블의 추가 | 집계 데이터를 위한 테이블을 생성하고, 각 원본 테이블에 트리거(Trigger)를 설정하여 사용하는 것 |
| 진행 테이블의 추가 | 이력 관리 등의 목적으로 추가하는 테이블 |
| 특정 부분만을 포함하는 테이블의 추가 | 데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블을 생성 |
- 트리거(Trigger) : 데이터베이스 시스템에서 데이터의 입력, 갱신, 삭제 등의 이벤트(Event)가 발생할 때마다 자동으로 수행되는 절차형 SQL
- 이력 관리 : 속성 값의 변화를 관리하기 위해 테이블에서 특정 속성 값이 변경될 때마다 변경되기 전의 속성 값을 저장하는 것을 말함
46.5 중복 속성 추가
조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것- 중복 속성을 추가하면 데이터의 무결성 확보가 더 어렵고, 디스크 공간이 추가로 필요
- 중복 속성을 추가하는 경우
- 조인이 자주 발생하는 속성인 경우
- 접근 경로가 복잡한 속성인 경우
- 액세스의 조건으로 자주 사용되는 속성인 경우
- 기본키의 형태가 적절하지 않거나 여러 개의 속성으로 구성된 경우
47. 시스템 카탈로그(System Catalog)
47.1 시스템 카탈로그(System Catalog)
시스템 그 자체에 관련이 있는 다양한 객체에 관한 정보를 포함하는 시스템 데이터베이스- 시스템 카탈로그 내의 각 테이블은 사용자를 포함하여 DBMS에서 지원하는 모든 데이터 객체에 대한 정의나 명세에 관한 정보를 유지 관리하는 시스템 테이블
- 카탈로그들이 생성되면 데이터 사전(Data Dictionary)에 저장되기 때문에 좁은 의미로는 카탈로그를 데이터 사전이라고도 함
47.2 메타 데이터(Meta-Data)
시스템 카탈로그에 저장된 정보를 의미- 메타 데이터의 유형
| 유형 | 내용 |
|---|---|
| 데이터베이스 객체 정보 | 테이블(Table), 인덱스(Index), 뷰(View) 등의 구조 및 통계 정보 |
| 사용자 정보 | 아이디, 패스워드, 접근 권한 등 |
| 테이블의 무결성 제약 조건 정보 | 기본키, 외래키, NULL 값 허용 여부 등 |
| 함수, 프로시저, 트리거 등에 대한 정보 |
47.3 데이터 디렉터리(Data Directory)
데이터 사전에 수록된 데이터에 접근하는 데 필요한 정보를 관리 유지하는 시스템- 시스템 카탈로그는 사용자와 시스템 모두 접근할 수 있지만 데이터 디렉터리는 시스템만 접근할 수 있음
48. 데이터베이스 저장 공간 설계
48.1 데이터베이스 저장 공간 설계
데이터베이스에 데이터를 저장하려면 테이블이나 컬럼 등 실제 데이터가 저장되는 공간을 정의해야 함| 객체 | 내용 |
|---|---|
| 테이블 (Table) |
- 데이터베이스의 가장 기본적인 객체 - 로우(Row, 행)와 컬럼(Column, 열)으로 구성되어 있음 - 데이터베이스의 모든 데이터는 테이블에 저장 |
| 컬럼 (Column) |
- 테이블의 열을 구성하는 요소 - 데이터 타입(Data Type), 길이(Length) 등으로 정의 |
| 테이블스페이스 (Tablespace) |
- 테이블이 저장되는 논리적인 영역 - 한 개의 테이블스페이스에 한 개 이상의 테이블을 저장할 수 있음 |
48.2 테이블 종류
| 종류 | 내용 |
|---|---|
| 일반 테이블 | - 대부분이 DBMS에서 표준 테이블로 사용되는 테이블 형태 - 데이터를 정렬하지 않고 가장 적절한 기억 장소에 저장한 후 임의의 방식으로 데이터를 관리하는 힙(Heap) 구조를 사용하므로 힙 구조 테이블(Heap-Organized Table)이라고도 함 |
| 클러스터드 인덱스 테이블 (Clustered Index Table) |
- 기본키(Primary Key)나 인덱스키의 순서에 따라 데이터가 저장되는 테이블 - 일반적인 인덱스를 사용하는 테이블에 비해 접근 경로가 단축 |
| 파티셔닝 테이블 (Partitioning Table) |
대용량의 테이블을 작은 논리적 단위인 파티션(Partition)으로 나눈 테이블 |
| 외부 테이블 (External Table) |
- 데이터베이스에서 일반 테이블처럼 이용할 수 있는 외부 파일 - 데이터베이스 내에 객체로 존재 |
| 임시 테이블 (Temporary Table) |
- 트랜잭션이나 세션별로 데이터를 저장하고 처리할 수 있는 테이블 - 임시 테이블에 저장된 데이터는 트랜잭션이 종료되면 삭제됨 |
49. 트랜잭션 분석 / CRUD 분석
49.1 트랜잭션(Transaction)
데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미- 데이터베이스 시스템에서 병행 제어 및 회복 작업 시 처리되는 작업의 논리적 단위로 사용
- 사용자가 시스템에 대한 서비스 요구 시 시스템이 응답하기 위한 상태 변환 과정의 작업 단위로 사용
- 물리 데이터베이스를 설계하려면 데이터베이스에 어떤 트랜잭션이 얼마나 자주 발생하는지 분석하고 그에 따라 트랜잭션 처리 방법이나 데이터베이스 구조 등을 설계해야 함
49.2 트랜잭션의 특성(ACID)
| 특성 | 의미 |
|---|---|
| Atomicity (원자성) |
트랜잭션의 연산은 데이터베이스에 모두 반영되도록 완료(Commit)되든지 아니면 전혀 반영되지 않도록 복구(Rollback)되어야 함 |
| Consistency (일관성) |
트랜잭션이 그 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 변환 |
| Isolation (독립성, 격리성, 순차성) |
둘 이상의 트랜잭션이 동시에 병행 실행되는 경우 어느 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없음 |
| Durability (영속성, 지속성) |
성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되어야 함 |
49.3 CRUD 분석
프로세스와 테이블 간에 CRUD 매트릭스를 만들어서 트랜잭션을 분석하는 것- CRUD 분석을 통해 많은 트랜잭션이 몰리는 테이블을 파악할 수 있으므로 디스크 구성 시 유용한 자료로 활용할 수 있음
49.3.1 CRUD 매트릭스
2차원 형태의 표로서, 행(Row)에는 프로세스를, 열(Column)에는 테이블을, 행과 열이 만나는 위치에는 프로세스가 테이블에 발생시키는 변화를 표시하여 프로세스와 데이터 간의 관계를 분석하는 분석표- CRUD 매트릭스를 통해 트랜잭션이 테이블에 수행하는 작업을 검증
- CRUD 매트릭스의 각 셀에는 Create, Read, Update, Delete의 앞 글자가 들어감
- 복수의 변화를 줄 때는 기본적으로 'C>R>U>D'의 우선순위를 적용하여 한 가지만 적지만, 활용 목적에 따라 모두 기록 가능
- 예) '주문 변경' 프로세스를 실행하려면 테이블의 데이터를 읽은(Read) 다음 수정(Update)해야 하므로 R과 U가 필요하지만 CRUD 매트릭스에서는 우선순위가 높은 U만 표시
- CRUD 매트릭스가 완성되었다면 C, R, U, D 중 어느 것도 적히지 않은 행이나 열, C나 R이 없는 열을 확인하여 불필요하거나 누락된 테이블 또는 프로세스를 찾음
- 온라인 쇼핑몰의 CRUD 매트릭스 예시
| 프로세스\테이블 | 회원 | 상품 | 주문 | 주문목록 | 제조사 |
|---|---|---|---|---|---|
| 신규 회원 등록 | C | ||||
| 회원정보 변경 | R, U | ||||
| 주문 요청 | R | R | C | C | |
| 주문 변경 | R | R, U | |||
| 주문 취소 | R, D | R, D | |||
| 상품 등록 | C | C, R | |||
| 상품정보 변경 | R, U | R, U |
49.4 트랜잭션 분석
CRUD 매트릭스를 기반으로 테이블에 발생하는 트랜잭션 양을 분석하여 테이블에 저장되는 데이터의 양을 유추하고 이를 근거로 DB의 용량 산정 및 구조의 최적화를 목적으로 함- 업무 개발 담당자가 수행
- 트랜잭션 분석을 통해 프로세스가 과도하게 접근하는 테이블을 확인할 수 있으며, 이러한 집중 접근 테이블을 여러 디스크에 분산 배치함으로써 디스크 입·출력 향상을 통한 성능 향상을 가져올 수 있음
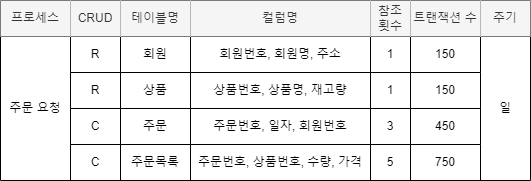
49.4.1 트랜잭션 분석서
단위 프로세스와 CRUD 매트릭스를 이용하여 작성- 구성 요소 : 단위 프로세스, CRUD 연산, 테이블명, 컬럼명, 테이블 참조 횟수, 트랜잭션 수, 발생 주기 등
- 예) '주문 요청' 프로세스에 대한 트랜잭션 분석서 예시
'자격증 > 정보처리기사' 카테고리의 다른 글
| 정보처리기사 - 데이터 입출력 구현 #55~57 (0) | 2023.08.19 |
|---|---|
| 정보처리기사 - 데이터 입출력 구현 #50~54 (0) | 2023.08.19 |
| 정보처리기사 - 데이터 입출력 구현 #44~45 (0) | 2023.08.19 |
| 정보처리기사 - 데이터 입출력 구현 #40~43 (0) | 2023.08.19 |
| 정보처리기사 - 데이터 입출력 구현 #36~39 (0) | 2023.08.19 |